How to stream big JSON files with low-memory footprint in Node.js
For production-grade applications, actions like reading a big file in memory is not ideal as they might cause OOM crash (Out Of Memory), and require a lot of resources for sometimes a really short duration. It would be a waste of resources and money to have a big server to only handle rare cases, and run at 5% of the capacity the rest of the time.
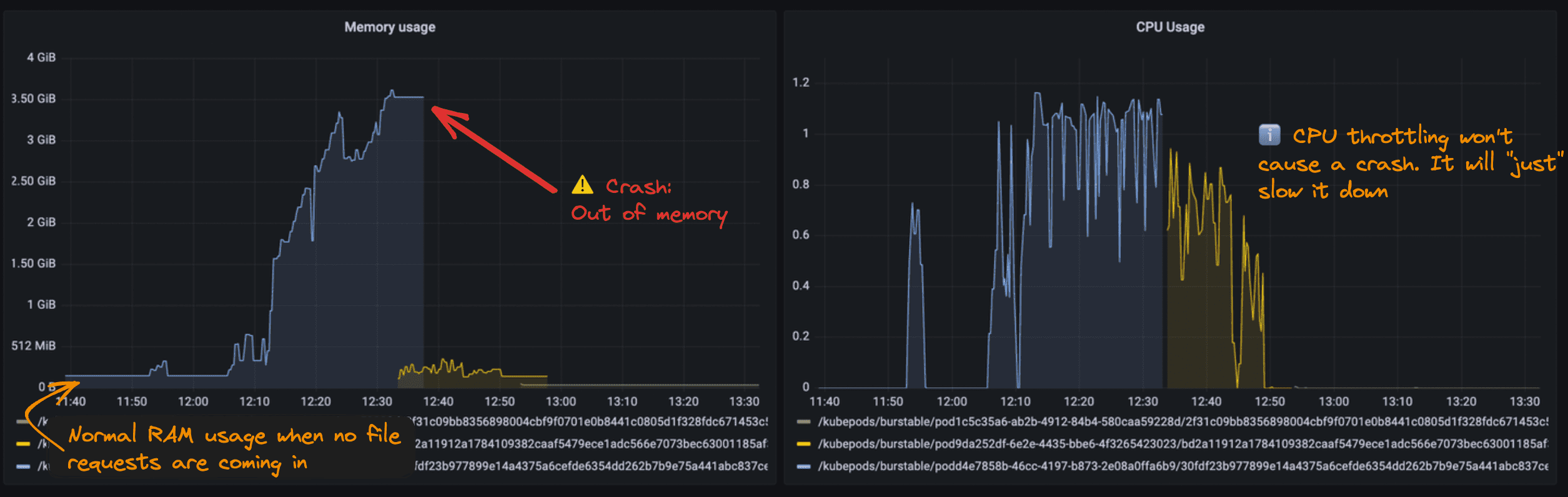
Legend: Example of a container with average memory consumption between 50 mb to 150 mb, when processing files it spikes to 4GB of RAM, leading to OOM crash.
Most of the time, especially with applications running on Kubernetes (like the one from the screenshot), a best practice is to stream data instead of loading it in memory. Here is how you can do it using Stream Transformers, a less-known Node.js feature.
Streaming big objects with nodejs
Generate data
Generate dummy data with this one-liner to paste in a terminal, to simulate a big JSON file.
node << EOF
require('node:fs').writeFile('dummy.json', JSON.stringify(
new Array(process.argv[2] || 50).fill({ id: 0, name: 'dummy' })
), _ => console.log('done'))
EOFJSON stream NPM Module
To help with processing JSON, we can use a tiny library like stream-json.
As written on the GitHub README:
stream-json is a micro-library of node.js stream components with minimal dependencies for creating custom data processors oriented on processing huge JSON files while requiring a minimal memory footprint. It can parse JSON files far exceeding available memory. Even individual primitive data items (keys, strings, and numbers) can be streamed piece-wise.
Install the json stream module:
npm install stream-jsonCode example
const { pipeline, Transform } = require("node:stream");
const fs = require("node:fs");
const { streamArray } = require("stream-json/streamers/streamArray");
const Batch = require("stream-json/utils/Batch");
const { parser } = require("stream-json");
const logMemory = () =>
console.log(
`Memory usage: ${
Math.round((process.memoryUsage().heapUsed / 1024 / 1024) * 100) / 100
} MB`
);
const sleep = (ms) => new Promise((resolve) => setTimeout(resolve, ms));
const customTransformer = new Transform({
objectMode: true, // to accept arrays
transform: async (chunk, encoding, cb) => {
logMemory();
console.log("chunk length: ", chunk.length);
await sleep(500);
cb();
},
});
pipeline(
// read from file
fs.createReadStream("dummy.json"),
// parse JSON
parser(),
// takes an array of objects and produces a stream of its components
streamArray(),
// batches items into arrays
new Batch({ batchSize: 2 }),
customTransformer,
(err) => {
if (err) {
console.error("Pipeline failed", err);
} else {
console.log("Pipeline succeeded");
}
}
);and it should give an output similar to:
➜ node-stream-demo node index.js
Memory usage: 4.6 MB
chunk length: 2
Memory usage: 4.64 MB
chunk length: 2
[...]
chunk length: 2
Memory usage: 4.32 MB
chunk length: 2
Memory usage: 4.33 MB
chunk length: 2
Memory usage: 4.33 MB
chunk length: 2
Pipeline succeededThe 2 interesting parts are in the pipeline() function:
new Batch({ batchSize: 2 })grouping data 2 by 2, very convenient to process data in batches.customTransformerto do async operations on the batches, like inserting data in a database by X.
Hope the example helps and provides ideas on how to use Node Stream Transformers!